We’ve filed a lawsuit challenging AI image generators for using artists’ work without consent, credit, or compensation.
Because AI needs to be fair & ethical for everyone.
This is Joseph Saveri and Matthew Butterick. In November 2022, we teamed up to file a lawsuit challenging GitHub Copilot, an AI coding assitant built on unprecedented open-source software piracy. In July 2023, we filed lawsuits on behalf of book authors challenging ChatGPT and LLaMA.
In January 2023, on behalf of three wonderful artist plaintiffs—Sarah Andersen, Kelly McKernan, and Karla Ortiz, we filed an initial complaint against Stability AI, DeviantArt, and Midjourney for their use of Stable Diffusion, a 21st-century collage tool that remixes the copyrighted works of millions of artists whose work was used as training data. Lockridge Grindal Nauen P.L.L.P. joined us as co-counsel.
In November 2023, we filed an amended complaint, adding seven new plaintiffs and one new defendant, Runway AI.
Case updates are posted regularly. You can also get updates by email.
The plaintiffs
Our plaintiffs are wonderful, accomplished artists who have stepped forward to represent a class of thousands—possibly millions—of fellow artists affected by generative AI.
Sarah Andersen

Sarah Andersen is a cartoonist and illustrator. She graduated from the Maryland Institute College of Art in 2014. She currently lives in Portland, Oregon. Her semi-autobiographical comic strip, Sarah’s Scribbles, finds the humor in living as an introvert. Her graphic novel FANGS was nominated for an Eisner Award. Sarah also wrote The Alt-Right Manipulated My Comic. Then A.I. Claimed It for the New York Times.
Kelly McKernan
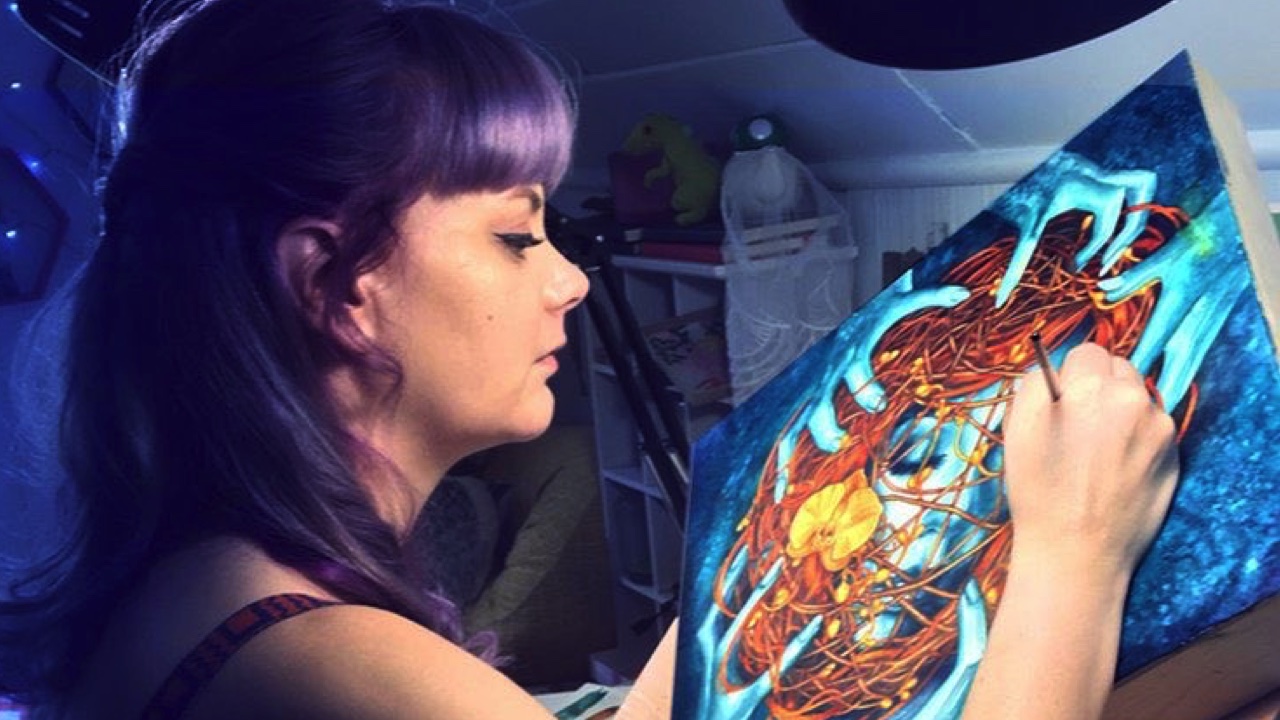
Kelly McKernan is an independent artist based in Nashville. They graduated from Kennesaw State University in 2009 and have been a full-time artist since 2012. Kelly creates original watercolor and acryla gouache paintings for galleries, private commissions, and their online store. In addition to maintaining a large social-media following, Kelly shares tutorials and teaches workshops, travels across the US for events and comic-cons, and also creates illustrations for books, comics, games, and more.
Karla Ortiz

Karla Ortiz is a Puerto Rican, internationally recognized, award-winning artist. With her exceptional design sense, realistic renders, and character-driven narratives, Karla has contributed to many big-budget projects in the film, television and video-game industries. Karla is also a regular illustrator for major publishing and role-playing game companies. Karla’s figurative and mysterious art has been showcased in notable galleries such as Spoke Art and Hashimoto Contemporary in San Francisco; Nucleus Gallery, Thinkspace, and Maxwell Alexander Gallery in Los Angeles; and Galerie Arludik in Paris. She currently lives in San Francisco with her cat Bady.
Hawke Southworth

Hawke Southworth is an illustration and 3D artist who has been active in the online art community since 2006. He attended Laguna College of Art and Design in 2014. Since then, his focus has ranged from character and creature designs, to worldbuilding, ARPG community building, and game development. He currently works as a freelance designer and runs an up-and-coming Art Roleplaying Game website, featuring his own creature designs and an eclectic fantasy world that users can interact with.
Grzegorz Rutkowski

Grzegorz Rutkowski is a Polish fine artist, digital painter, illustrator, and concept artist. He started his professional career in 2009. He has worked for companies like Wizards of the Coast, Ubisoft, Blizzard, Disney, CD Projekt RED, Games Workshop and many more. He lives in Poland with his wife and two daughters.
Gregory Manchess

Gregory Manchess has created artwork for National Geographic Magazine, Time, Atlantic Monthly, and The Smithsonian. His large portrait of Abraham Lincoln and seven other paintings are highlighted in the Abraham Lincoln Presidential Library and Museum. Manchess wrote and illustrated his first ‘widescreen novel’ Above the Timberline, released in 2017 to stellar reviews. The Society of Illustrators presented him with their highest honor, the Hamilton King Award, in 1999. Today, Gregory lectures at universities and colleges nationwide and gives workshops in painting at the Norman Rockwell Museum in Stockbridge MA, and The Atelier in Minneapolis. He teaches at the Illustration Master Class in Savannah GA and online with SmArt School.
Gerald Brom

Artist and author Gerald Brom has been contributing his macabre and often bizarre visions to all facets of the creative industries for forty years, including major motion pictures, top-tier video games, comics, and books. He has also written and illustrated six horror novels, including such popular titles as The Child Thief, Krampus the Yule Lord, Lost Gods, and Slewfoot.
Jingna Zhang

Jingna Zhang is a Beijing-born, US-based Singaporean photographer whose award-winning works have appeared in Vogue, Time, and Harper’s Bazaar. Inspired by the Pre-Raphaelites and anime, her romantic images interweave Asian influences with painterly art styles, and feature collaborators such as Coco Rocha, Sugizo, and Michelle Yeoh. Prior to photography, Jingna was an agent and consultant for concept artists and illustrators with clients spanning LucasArts, Amazon Publishing, and Sony Music Japan. Jingna is currently the founder of Cara, a platform for discovering human artists.
Julia Kaye

Julia Kaye is an LA-based storyboard artist & revisionist with over six years of industry experience, and the award-winning author of two critically acclaimed graphic novels: Super Late Bloomer and My Life in Transition. Her commitment to activism has led to collaborations with non-profit organizations such as The Trevor Project and Trans Lifeline. Her work has appeared on Webtoon, GoComics, Buzzfeed, and the Disney animated show Big City Greens.
Adam Ellis

Adam Ellis is a comic artist and illustrator who lives in New York City. When he’s not drawing he’s watching documentaries about cults and dreaming about one day owning a backyard big enough to keep chickens.
The defendants
Stability AI
Stability AI, founded by Emad Mostaque, is based in London.
Stability AI funded LAION, a German organization that is creating ever-larger image datasets—without consent, credit, or compensation to the original artists—for use by AI companies.
Stability AI is the developer of Stable Diffusion. Stability AI trained Stable Diffusion using the LAION dataset.
Stability AI also released DreamStudio, a paid app that packages Stable Diffusion in a web interface.
DeviantArt
DeviantArt was founded in 2000 and has long been one of the largest artist communities on the web.
As shown by Simon Willison and Andy Baio, thousands—and probably closer to millions—of images in LAION were copied from DeviantArt and used to train Stable Diffusion.
Rather than stand up for its community of artists by protecting them against AI training, DeviantArt instead chose to release DreamUp, a paid app built around Stable Diffusion. In turn, a flood of AI-generated art has inundated DeviantArt, crowding out human artists.
Midjourney
Midjourney was founded in 2021 by David Holz in San Francisco. Midjourney offers a text-to-image generator through Discord and a web app.
Though holding itself out as a “research lab”, Midjourney has cultivated a large audience of paying customers who use Midjourney’s image generator professionally. Holz has said he wants Midjourney to be “focused toward making everything beautiful and artistic looking.”
To that end, Holz has admitted that Midjourney is trained on “a big scrape of the internet”. Though when asked about the ethics of massive copying of training images, he said “There are no laws specifically about that.”
Runway AI
Runway was founded in New York in 2018 by Anastasis Germanidis, Alejandro Matamala-Ortiz and Cristóbal Valenzuela. Runway also employs Patrick Esser, formerly a member of the CompVis research group at Ludwig Maximilian University in Munich, where he was a principal developer of the technology underlying Stable Diffusion.
Contacting us
If you’re a member of the press or the public with other questions about this case or related topics, contact stablediffusion_inquiries@saverilawfirm.com. (Though please don’t send confidential or privileged information.)
If you’d like to receive occasional email updates on the progress of the case, click here to sign up.